Section 10 Example: Interaction with Praat
This example needs data in Praat files with annotation on phoneme level. This is very time consuming to create, but as we saw in Example 1, we can get almost readily usable data through already existing tools using the forced alignment methods offered by Munchen University.
So the data we have in hand looks like this:
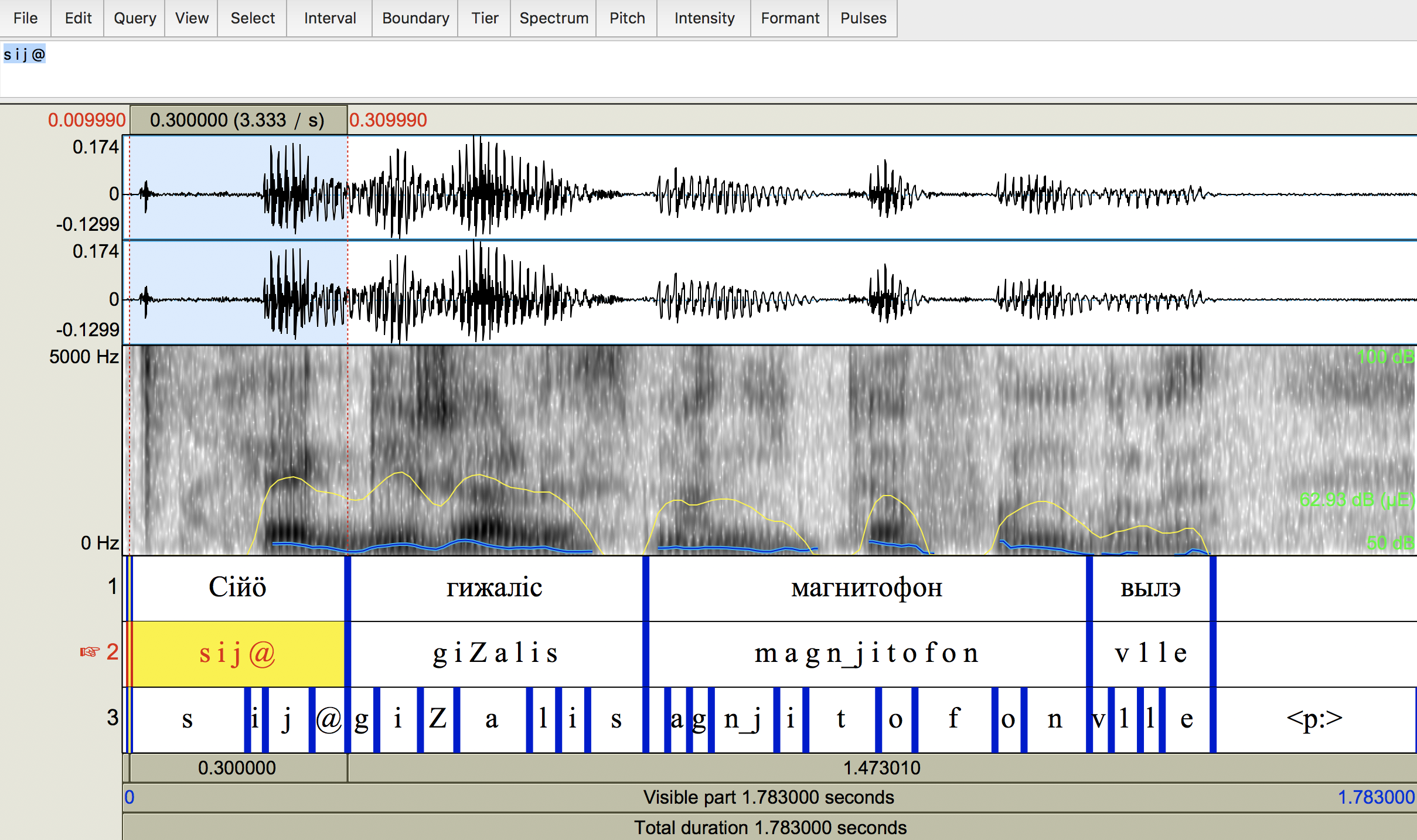
10.1 Research questions
- Out of the annotated vowels, which are correctly analysed and which are somehow wrong?
- How do the vowel formants plot
- Can we very easily identify the wrongly analysed ones and correct those?
10.2 Implementation
We are using several smaller tools here:
sendpraatto communicate with PraatPraatScriptto extract the formants and write.formantfiles- R to read those files and reshape those into a nice dataframe
- R to plot the output
- Shiny R package to wrap this into a shallow interface
10.3 Shiny application
The application looks like below.
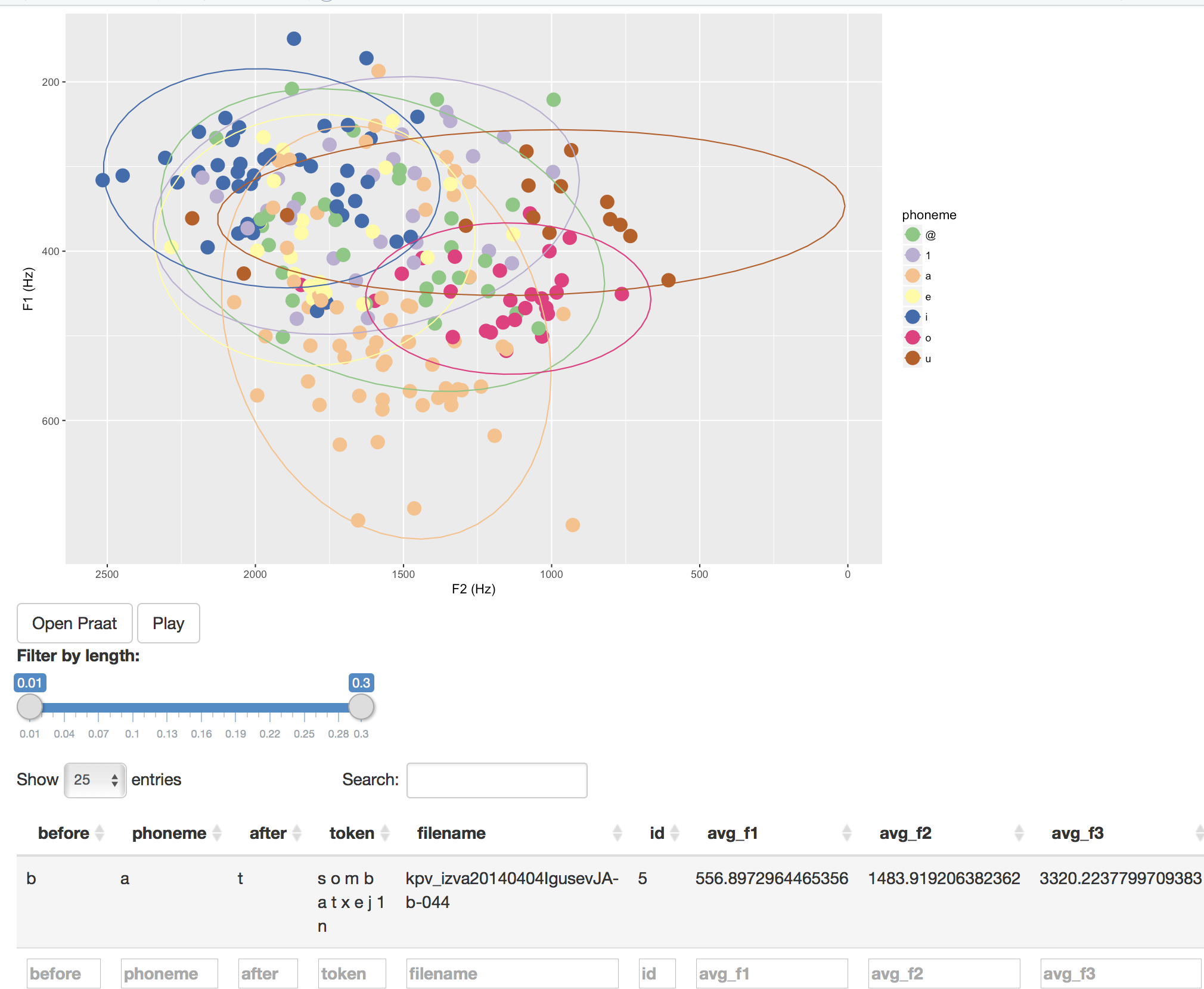
It has only a few functionalities:
- Select the vowel by clicking it
- See what is selected under the plot
- Open the current selection in Praat
- Play the word where the currently selected vowel is
- Filter by length (not really useful in this case, but worth checking)
Some of these are compromises in a way. It is easy to set up the file to open in Praat, but this of course works only locally. It is not possible to deploy an app like this online. This leads into new questions. How much effort should we pay to make the tool maximally reusable? The question is not trivial, as setting up it more complexly would easily lead into tens of hours spent with adjusting things. In some cases it is useful just to say that this works for me, this is how I use it, this is enough for now. Put the code into GitHub and hope someone else fixes the harder problems.
10.4 Observations
- There are vowel reductions in faster speech which are not very well described in Komi
- It seems that the Russian and Komi vowels plot differently, do they?
10.5 Exercise
How would you test if the Russian and Komi vowels plot differently? Hints: Skip for now the linguistic part of the question, just think how you get this information into the program. Also skip the statistical part of how you actually verify what you have, this is very simple exercise which is supposed to illustrate moving data in and out.