4 FAIR principles
Since 2016 so-called FAIR principles have become increasingly commonly discussed in the context of research data. The acronym is created from words Findable, Accessible, Interoperable and Reusable. This describes the idea well.
Personally I think the best thing in FAIR is that it leads various scientific disciplines to discuss these matters with the same concepts, and different components of FAIR principles are well identified. At the same time I find FAIR bit of a mixture of very concrete recommendations and abstract concepts. Some of them are better met with the current infrastructure and practices than others.
FAIR is often described as a wheel of some sort, with the arrows indicating movement from one phase to another.
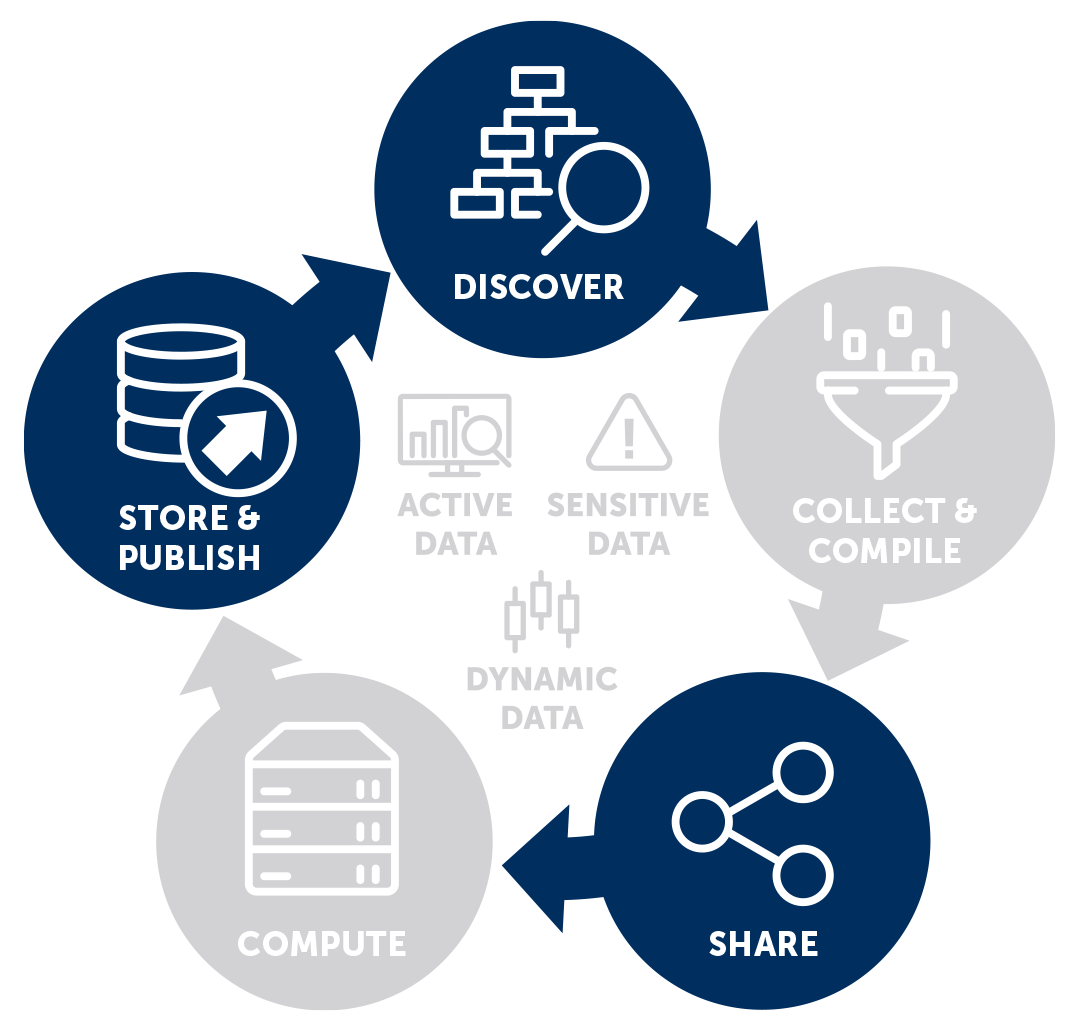
CSC’s Fairdata image
At times the principles are illustrated also as some type of a puzzle where the parts just belong together.
!1(media/fair-principles.png){width=50%}
4.1 Findable
By findable it is meant that the data can be uniquely distinguished from other materials, and it is described in a manner that points an interested user accurately toward it. Persistent identifier is an important part of this, and any data repository we decide to use should provide this automatically, ideally immediately when the data is first described. The dataset creator should bother primarily with the description itself, as the metadata indexing and identifier creation should happen within the repository.
Metadata indexing means that once the resource is described, it will pop up in various aggregating search platforms. For example, language resources are harvested from many locations into Virtual Language Observatory. But this is already specific to different repositories. This is possible only when metadata is machine readable. This means that it uses standards and definitions shared by all materials in a given repository, or those that are used in a given scientific field.
There is a long history of describing metadata for materials that never end up being deposited anywhere. This is not a really good thing. I think this has impacted negatively in how some larger repositories are perceived, because so many have an experience of finding something interesting, but not being able to access the materials themselves. Disclaimer: I have done this myself! It is often easy to describe something in a very initial phase of the project, but finishing it is usually a different matter.
I would actually recommend not to describe public metadata much before you are truly ready to submit the actual materials. At the same time we are developing the idea that, for example, archived linguistic materials, should be archived very early and be updated incrementally, so maybe we will see workflows where both the metadata and the dataset grow organically while a project team works on it along the years. This is discussed further in the Section on versions.
This discussion about metadata not actually pointing to the described resource leads to the next section, which is about accessibility.
4.2 Accessible
Accessible in this context means that it should be possible to access the data with a normal computer and internet connection. Maybe the spirit of the description would also indicate some programmatic access, but I don’t think we are very often in that point yet.
One important aspect here is that the access method to the dataset should allow authentication when that is necessary. Indeed, when we discuss FAIR principles, we are not talking only about openly accessible data. Lots of research materials cannot be made open, but may need to adhere into different access requirements. For example, for some materials only scientific use is permitted, so there has to be some mechanism to verify and control to what uses the data is distributed for. This is particularly important with data that contains personal data. You can read more in Section Open Access.
One specific type of access restriction is embargo. This means that the data is deposited and described, but it can be accessed only after some specific time has passed. This is a very reasonable request if, for example, someone is writing an article or thesis about the dataset, and wants that to be submitted, accepted or published before the data is made more openly available. There are no rules in this (I think), but a reasonable embargo period would thereby be closely connected to expected times such research projects usually can last.
There are also examples of unreasonable embargo periods. In the University Library of Jyväskylä in Finland there is a closet sealed by Finnish researcher Eliel Lagercrantz, which can be opened 300 years after his birth in 26.12.2194.

Unreasonable embargo pictured. Image: StultuS, Wikimedia Commons, CC BY-SA
{kind=link}
No matter what the access requirements, the metadata should make it clear what these demanded conditions are. A clear license is the best approach to this, since then we are immediately on a (quite) common ground about the possible reuse.
One good example about managing the access is LBR-system is the Language Bank of Finland. The researcher can log in, add resources into a basket, write an explanation about their use, and someone will approve or decline the request. I think we are still very much developing the practices of who actually does these approvements, but at least in LBR system they have managed to make this a good experience for the user, and apparently also effortless for the approver. There are other systems like this which demand very technically complex applications, which may be a burden for both participants.
Not all data lives forever. In some studies there are fixed periods of how long the data is stored, and some repositories promise the storage periods of 10 or 50 years, for example. This connects partly to the longetivity and durability of institutions as well: promising that something is stored essentially forever, would demand that there is some organization always handling this work. This is not possible, and for some research data not even reasonable. However, one idea of FAIR is that at least the metadata would be stored after the data has been destroyed, so that some accountability and description does remain.
Of course there is also a curious relation between research data and cultural data. The materials we collect and refine now will in decades and centuries blur with other materials that represent this period we live in, and it’s a good question what is the exact relation or difference here. Also in our contemporary work we may often use materials that have been collected in 1870s or 1880s, or earlier, and of course as time passes also the artefacts we create do have this widening temporal dimension.
4.3 Interoperable
By interoperable we mean that the data and metadata, following FAIR principles, should be usable and understandable for another specialist of your field. This means that we should use formats and vocabularies that are commonly used in our field.
One thing I want to emphasize with formats is that the format alone is only part of the picture. Yes, we should use formats that are typical for our field, and if we use something else, we should pay extra attention to the documentation of those decisions. However, the use of valid format doesn’t help us very much if the fields within the format are empty or incorrectly filled. Additionally, some formats are lax, and allow various customization. This is particularly typical for some XML structures used with linguistic data. It is a good step forward if we know that a file is, for example, ELAN XML file that contains transcriptions, but if the files are not fully consistent and the structures used are not documented, we are still really far away from being able to use these materials in a truly interoperable manner.
I personally feel a dataset is interoperable if I don’t have to fix it very much before I can use it. I also think that we should keep the mindset where we are intelligent people doing materials that will be used by other intelligent people. So the bar is not really at the level where everything has to be automagically interoperable without thinking anything, but we should not invent a wheel again every time there is a new dataset.
One part of interoperability is also that the data is linked to relevant datasets and resources. This could mean the materials from which the dataset is originally created, or publications where it has been used. Further use of datasets inevitable leads into new versions and additional datasets, so if possible, links to these are also very important. That said we do not really have a clear way to always follow where distinct datasets are used, no matter how good our identifiers and other practices. Adhering to common citation practices is one way through which we try to develope this further.
4.4 Reusable
Reusability refers to both possibility to understand easily what this data can be used for, and also to concrete conditions of doing this if so desired. The background of the dataset should be described so that the limitations and general scope of the material is understandable. License, which was discussed already above, connects to this section strongly, as it is one important condition for the further reuse.
The background, or provenance, is a central question here. Who collected the data, in which conditions, and funded by which entity? What was the exact process in which these materials were created? What was the goal of creating them in the first place? Especially important is to indicate which other your data includes data from somewhere else, or if it has been published before somewhere. We will discuss this further in Section Starting a dataset.
Software is usually discussed in the context of reusability. I think this is especially important when we create a dataset from another dataset, and when it is done programmatically by querying or extracting a specific part of the resource, and possibly combining it with something else. In these cases recommendable scenario is to store a specific reference to the original data, or maybe even the original data itself, and store separately also the code used to create the new version. Storing only the code is not necessarily enough, but more information should be given about the computing environment. Which version of the programming language was used, which package versions were installed and so on. I think the reality of these things is that we often cannot run that code successfully after more years have passed, and we shouldn’t obsess over this fact. Who knows, maybe it will run beautifully! The point is that by documenting this environment and storing the code itself we can arrive into a point where we have good conditions to exactly understand what was done, and where the possible differences arise from.
There are also very specific conditions at times. For example, in CLARIN infrastructure there have been materials that can be redistributed within CLARIN. This means that it is possible to reuse the materials and publish them, but not anywhere. This is, at least in theory, a very convenient way to publish new versions of materials that cannot be made openly available. To my knowledge this has not been very commonly done, at least in Finland, but it’s a good idea.
4.5 Are we actually doing this?
As mentioned, we often see FAIR described as a kind of circle. However, I’m personally little bit sceptical about how well we are truly doing with this. I would argue that the situations where new datasets are created are still much more common that actual reuse of old data – not to even mention datasets that have been edited and republished.
All these ideas we have discussed in relation to FAIR are very good. I think technically and methologically they really encompass very large part of what we have to take into account while working with our research data, if we truly want to make it open and reusable. Many aspects not even recommendations, but demands. We have to think of licenses, we have to understand where the data comes from, we have to know if we actually are allowed to do what we are doing.
But I do think that we really need to see a shift from creating new datasets to combining and reusing those that already exist. I may be blinded by my linguistics background, where I certainly do not see this happening.